




Как работает поисковая система



Cооснователь Российской школы SEO
На момент зарождения интернета (конец 90-ых годов) число сайтов измерялось сотнями. В 2012 году эта цифра составляла более 1 млн. в день. На 2018 год в сети появляются более 47 млн. сайтов каждый месяц. Как поисковые системы способны найти, обработать и предоставлять их пользователю? В данной статье разложим пошагово все компоненты от момента регистрации домена до появления страниц в результатах выдачи.
Роботами будем называть специальные программы поисковых систем, которые способны самостоятельно находить информацию о web-сайтах в интернете и обрабатывать её на основе заложенных алгоритмов.
Давайте разделим весь процесс работы поисковика с сайтом на несколько отдельных этапов, которые идут друг за другом:
- Включение домена в базу робота.
- Получение информации о страницах, расположенных на домене.
- Обработка контента на этих страницах.
- Сортировка и публикация web-документа в результатах поисковой выдачи.
Как поисковик узнает о новом домене
Несмотря на широкие возможности, робот может долго не знать о существовании вашего сайта. Для сбора данных поисковик использует различные ресурсы, один из которых, рано или поздно, даст знать о появлении нового сайта. Какие же ресурсы используют поисковый робот для сканирования интернета:
- Ссылки с уже известных доменов;
- Действия пользователей (e-mail переходы из почт, социальных сетей, рекламных площадок, мессенджеров и любые переходы, которые можно отследить);
- Браузеры (Яндекс.Браузер, Google Сhrome и другие собирают анонимные данные о пользователях для собственной статистки);
- Установка сервисов поисковых систем (Яндекс.Метрика, Google Analytics и т.д.);
- Выдача других поисковиков, в которых уже появился сайт.
Вариантов мониторинга очень много. Но самый верный способ сообщить о новом сайте – добавить его в вебмастер того поисковика, в котором сайт должен отображаться. Например, для Яндекса это webmaster.yandex.ru, а для google - google.ru/webmasters. После добавление в течение 1-7 дней робот обязательно посетит страницы сайта.
Процессом сканирования ссылок в интернете занимаются пауки (веб-паук, веб-краулер, бот, web-crawler) – специализированные программы, которые переходят по всем доступным страницам на домене и отправляют найденные URL-адреса в основную часть поискового робота для последующего анализа. Краулер не занимается обработкой контента самостоятельно. Цели веб-паука:
- Найти все возможные адреса страниц;
- Отправить новые страницы для последующего анализа в поисковую базу;
- Если старые страницы были изменены с момента последнего захода, то также отправить для анализа;
- Помимо обхода задача веб-краулера – сохранить ресурс анализатора. Поэтому он должен четко определить, что текущая версия страницы уже есть в базе, и не нужно её отправлять повторно.
Стартовая панель - Яндекс.Вебмастер
Стартовая панель - Google.Search.Console
Как происходит добавления страниц сайта в базу поисковика
Когда поиск знает о существовании домена, то с определенной периодичностью робот будет сканировать и индексировать его.
Индексирование – процесс обработки страниц сайта с целью последующего добавления новых страниц или обновлённых старых в поисковую выдачу. Во время анализа робот оценивает вероятность попадания страницы в зону видимости для пользователя.
На старте все сайты получают примерно равные квоты на частоту сканирования (переобхода страниц). Со временем для постоянно обновляемых ресурсов квота расширяется, и роботы чаще посещают сайт. Для менее обновляемых сайтов эта квота снижается. Поэтому так важно проводить постоянно хотя бы в минимальных количествах изменения на домене.
О новых или измененных страницах поисковик узнает, используя те же способы, что и для поиска доменов. Но к ним добавляются:
- Внутренние ссылки между страницами индексируемого сайта;
- XML-карта (sitemap.xml) – страница внутри сайта, содержащая дерево ссылок на все полезные URL-адреса;
- Ручное добавление новых url-адресов в вебмастер.
Работая с вышеуказанными инструментами, мы можем напрямую влиять на частоту индексирования нашего сайта.
Анализ контента. Прогноз попадания страницы в выдачу
Когда страница находится в базе поисковика, ему нужно оценить – насколько текущая версия будет полезна для пользователей. Обработкой и прогнозом занимается анализатор - обособленная часть поисковой системы. Если страница признается полезной, то в ближайшие текстовые апдейты она появится в результатах органической выдачи.
Апдейт в seo – обновление поисковой выдачи. Она может обновлять в результате пересчета уже имеющихся данных о страницах, либо в результате добавления новых URL-адресов. Только во время текстового апдейта ранее не добавленная страница может попасть в выдачу.
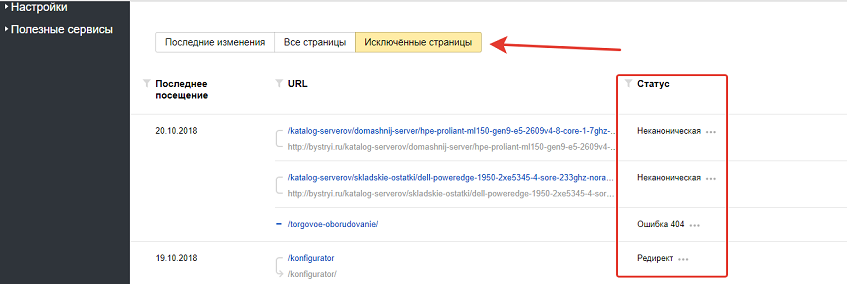
Почему страница может не попасть в поисковый индекс – причин много, но вот самые основные из них:
- контент частично или полностью дублируется с другими страницами в поисковой базе;
- бесполезный, малоинформативный контент на странице;
- контент насыщен рекламой;
- страница содержит очень мало текстового контента.
Яндекс.Вебмастер - отклоненные страницы
Ранжирование результатов выдачи
Робот узнал о странице и проанализировал её содержание. Но помимо этого URL-адреса в выдаче еще десятки, сотни или тысячи похожих страниц. Поэтому существует процесс ранжирования и группа факторов, влияющих на этот процесс.
Ранжирование – сортировка результатов поисковой выдачи на основе неких факторов. В разных поисковиках свои факторы ранжирования, но они все очень похожи. Их задача – посредством математических алгоритмов рассчитать полезность страницы для пользователя в рамках конкретного запроса. На 2018 год представители поисковиков заявляют о сотнях факторов.
Каждый раз при обновлении поисковой базы робот производит пересчет значений сайта для последующего ранжирования, поэтому после апдейтов позиции сайта изменяются.
Итоговая цепочка появления страницы в выдачи выглядит так:
1. Добавление в базу поисковика информацию о новом домене.
2. Сканирование и добавление новых URL-адресов для последующей обработки.
3. Анализ контента новых страниц – добавление/отклонение URL в поисковый индекс.
4. Расчет качества страницы и появление в результатах выдачи на определенных позициях.
Публикации раздела





